![[GECCO 2023] Rethinking Population-assisted Off-policy Reinforcement Learning](https://www.emigroup.tech/wp-content/uploads/2023/04/未命名的设计-1-840x420.png)
Bowen Zheng, Ran Cheng*
Abstract:
While off-policy reinforcement learning (RL) algorithms are sample efficient due to gradient-based updates and data reuse in the replay buffer, they struggle with convergence to local optima due to limited exploration. On the other hand, population-based algorithms offer a natural exploration strategy, but their heuristic black-box operators are inefficient. Recent algorithms have integrated these two methods, connecting them through a shared replay buffer. However, the effect of using diverse data from population optimization iterations on off-policy RL algorithms has not been thoroughly investigated. In this paper, we first analyze the use of off-policy RL algorithms in combination with population-based algorithms, showing that the use of population data could introduce an overlooked error and harm performance. To test this, we propose a uniform and scalable training design and conduct experiments on our tailored framework in robot locomotion tasks from the OpenAI gym. Our results substantiate that using population data in off-policy RL can cause instability during training and even degrade performance. To remedy this issue, we further propose a double replay buffer design that provides more on-policy data and show its effectiveness through experiments. Our results offer practical insights for training these hybrid methods.
Results:

Figure 1: Empirical analyses on Mujoco locomotion tasks. For our tailored ERL algorithms (always-first, always, normal), the average returns of the population mean are drawn by dash lines with the same corresponding color.
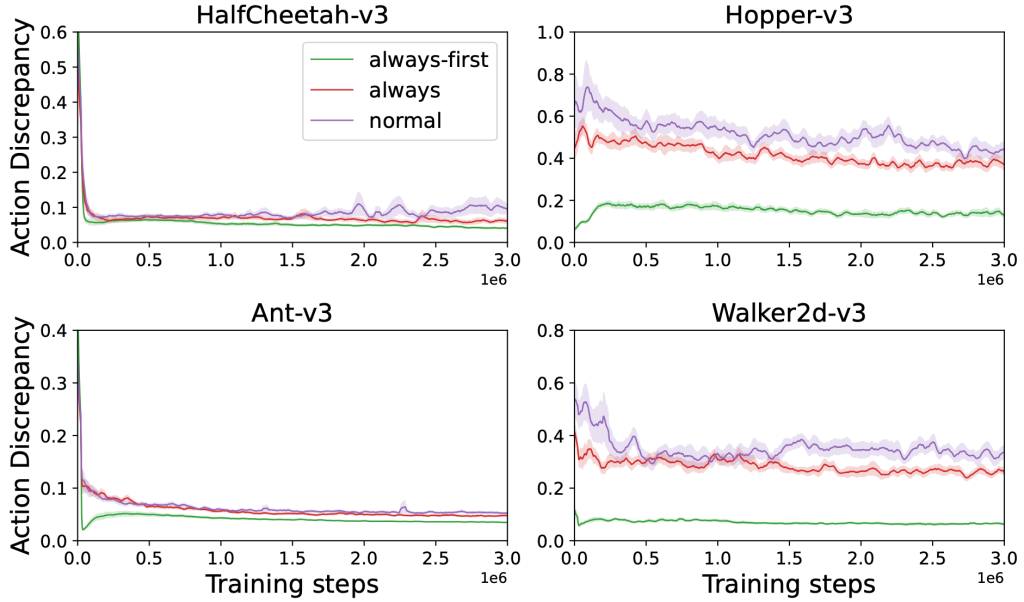
Figure 2: The average action discrepancy between the target actor and population actors in the empirical analyses.

Table 1: The final performance of no-pop, param-noise and our tailored ERL with the remedy method.
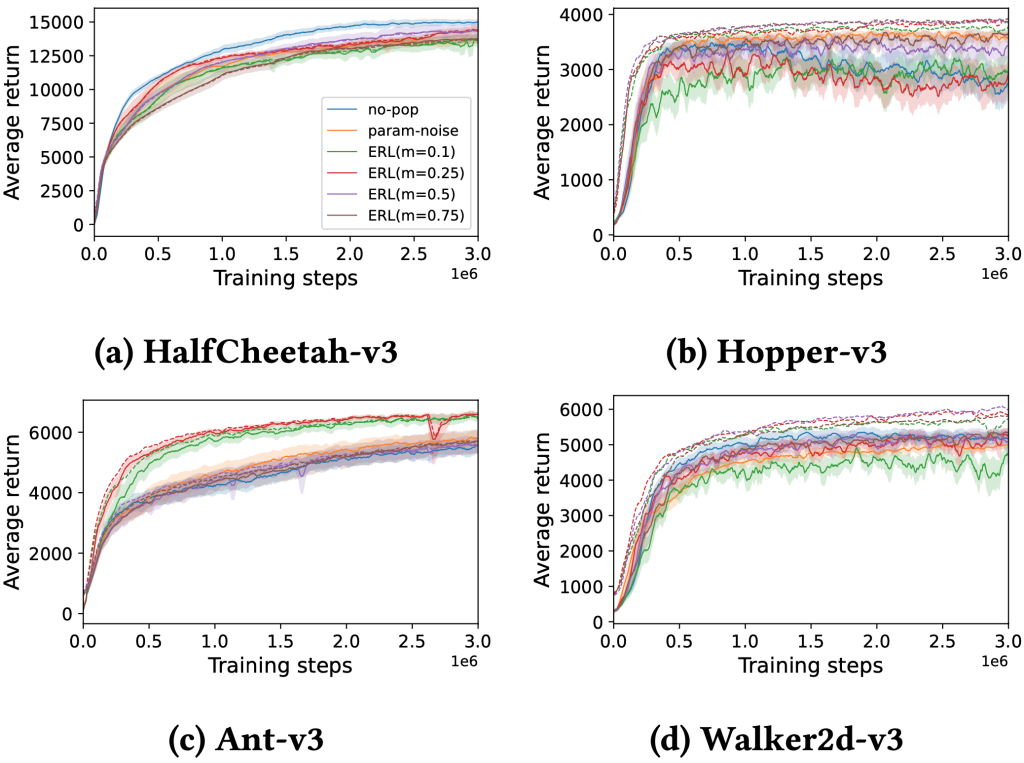
Figure 3: Learning curves of no-pop, param-noise and our tailored ERL algorithm with the remedy method on Mujoco tasks. The average return of the population mean in ERL is drawn by dash lines with the same color.
Acknowledgments:
This work was supported by the Program for Guangdong Introducing Innovative and Entrepreneurial Teams (Grant No. 2017ZT07X386).