![[IEEE TAI] SoloGAN: Multi-domain Multimodal Unpaired Image-to-Image Translation via a Single Generative Adversarial Network](https://www.emigroup.tech/wp-content/uploads/2022/06/6-840x358.png)
Abstract
Despite significant advances in image-to-image (I2I) translation with generative adversarial networks (GANs), it remains challenging to effectively translate an image to a set of diverse images in multiple target domains using a single pair of generator and discriminator. Existing I2I translation methods adopt multiple domain-specific content encoders for different domains, where each domain-specific content encoder is trained with images from the same domain only. Nevertheless, we argue that the content (domain-invariance) features should be learned from images among all of the domains. Consequently, each domain-specific content encoder of existing schemes fails to extract the domain-invariant features efficiently. To address this issue, we present a flexible and general SoloGAN model for efficient multimodal I2I translation among multiple domains with unpaired data. In contrast to existing methods, the SoloGAN algorithm uses a single projection discriminator with an additional auxiliary classifier and shares the encoder and generator for all domains. Consequently, the SoloGAN can be trained effectively with images from all domains such that the domain-invariance content representation can be efficiently extracted. Qualitative and quantitative results over a wide range of datasets against several counterparts and variants of the SoloGAN demonstrate the merits of the method, especially for challenging I2I translation datasets, i.e., datasets involving extreme shape variations or need to keep the complex backgrounds unchanged after translations. Furthermore, we demonstrate the contribution of each component in SoloGAN by ablation studies.Results

Figure 1: Qualitative comparison between SoloGANs and existing methods.
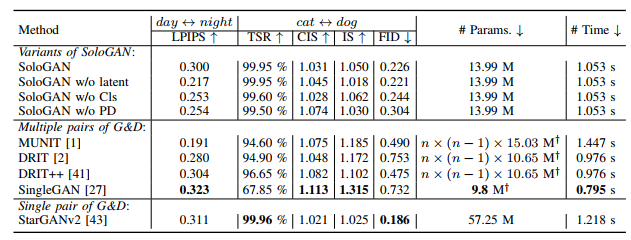
Table 1: Quantitative comparison between SoloGANs and existing multimodal methods.

Figure 2: Example-guided Image-to-Image Translations.
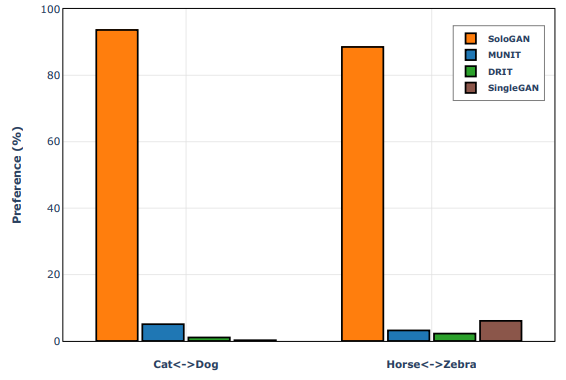
Figure 3: Human evaluation results collected from 100 reports, where vertical axis indicates percentage of preference. Higher value indicates a majority of users prefer images generated by corresponding method in terms of realistic details and translation success.
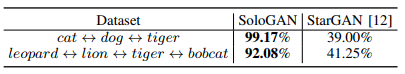
Table 2: Quantitative comparison between SoloGAN and StarGAN.
Acknowledgments:
This work was supported by the National Natural Science Foundation of China (No. 61906081 and U20A20306), the Shenzhen Science and Technology Program (No. RCBS20200714114817264), the Guangdong Provincial Key Laboratory (No. 2020B121201001), and the Program for Guangdong Introducing Innovative and Entrepreneurial Teams (Grant No. 2017ZT07X386).Citation
@ARTICLE{huang2022sologan,
author={Huang, Shihua and He, Cheng and Cheng, Ran},
journal={IEEE TAI},
title={SoloGAN: Multi-domain Multimodal Unpaired Image-to-Image Translation via a Single Generative Adversarial Network},
year={2022}
}